RMX203
20.08.2026
Telefon: +49 (511) 365 53 43 oder folge uns auf
Ob SQL-Anfänger oder Query Experte, von Zeit zu Zeit liefern uns SQL-Abfragen in der Marketing Cloud nicht die gewünschten Ergebnisse. Die Gründe hierfür sind vielfältig und teilweise spezifisch für die Marketing Cloud.
In diesem Artikel schauen wir uns die häufigsten Gründe für fehlerhafte SQL-Ergebnisse in der Marketing Cloud an und wie wir diese vermeiden können.
Bei einer Marketing Cloud Umgebung mit mehrerer Business Units gibt es eine Business Unit Hierarchie. Demnach gibt es eine sogenannter Enterprise Business Unit, der alle weiteren Business Units untergeordnet sind, als sogenannter Child Business Units.
Wenn man von einer solchen Child Business Unit mit einer SQL auf geteilte Data Extensions zugreifen möchte, muss immer das Präfix “ENT.” an den Namen der Data Extension angefügt werden.
Bsp.: Ent.Contact_Salesforce_01
Dies gilt für:
Hinweis:
Die All Subscribers Liste wird über alle Business Units hinweg geteilt. Egal aus welcher Business Unit auf die All Subscribers Liste zugegriffen wird, man sieht immer alle Subscriber für den gesamten Marketing Cloud Account.
Mit Hilfe der Data View Tables kann man auf Subscriber Informationen zugreifen, die auch an der All Subscribers Liste zu finden sind. Da es sich jedoch um geteilte Informationen handelt, muss auch hier der Präfix ENT. angefügt werden, wenn die SQL in einer Child Business Unit ausgeführt wird.
Geschieht dies nicht, enthält das Ergebnis 0 Datensätze. Hierzu gibt es leider keine entsprechende Fehlermeldung bei der Validierung der SQL.
Sämtliche Datumsfelder in der Marketing Cloud bestehen immer aus dem Datum und der Uhrzeit.
Bsp.: 1/1/2024 12:00:00 AM
Vergleicht man ein Datumsfeld direkt mit einem anderen Datumsfeld, werden nur diejenigen Datensätze angezeigt, die exakt das gleiche Datum und die gleiche Uhrzeit aufweisen.
Falsch:StartDate = GETDATE()
Um ein Datum (ohne Uhrzeit) mit einem anderen vergleichen zu können, müssen die Datumsfelder daher formatiert werden.
Richtig:Format(StartDate, 'yyyy-MM-dd') = Format(GETDATE(), 'yyyy-MM-dd')
Hinweis:
Die Funktion „Format“ verwandelt das Datum in einen String, also in Text. Bei einem größer/kleiner Vergleich von Datumsfeldern ist es daher wichtig, dass mit dem größten Wert begonnen wird, in diesem Fall mit dem Jahr (yyyy).
Falsch:Format(StartDate, 'dd-MM-yyyy') > Format(GETDATE(), 'dd-MM-yyyy')
Ergebnis: alles was größer als 01-01-2024 ist. z.B.: 02-01-2023
Richtig:Format(StartDate, 'yyyy-MM-dd') > Format(GETDATE(), 'yyyy-MM-dd')
Ergebnis: alles was größer als 2024-01-01 ist. z.B.: 2024-01-02
In international agierenden Unternehmen kann es vorkommen, dass Datumswerte, die in der Marketing Cloud landen, eine andere Zeitzonen enthalten.
Dies betrifft insbesondere auch die Server-Zeit der Marketing Cloud. Egal wo sich der Server befindet, die Server-Zeit in der Marketing Cloud ist IMMER Central America Standard Time (UTC-6) ohne Sommerzeit!
Selbst die Umstellung der Zeitzone in den Account Einstellungen hat keinen Einfluss auf die Server-Zeit.
Folgende von der Marketing Cloud definierte Datumswerte sind davon betroffen:
Mit der Funktion AT TIME ZONE können Datumsfelder in die richtige Zeitzone formatiert werden.
Bsp.:SELECT FORMAT(GETDATE() AT TIME ZONE 'Central America Standard Time' AT TIME ZONE 'Central European Standard Time', 'dd-MM-yyyy') as Today
In den meisten Fällen ist ein nicht gefülltes Feld in einer Data Extension NULL. Das bedeutet, dieses Feld enthält keinerlei Daten, nicht einmal Meta-Daten.
Wird ein Datensatz neu angelegt, egal ob über einen Import, eine SQL, einen Filter oder manuell, bekommen nicht gefüllte Felder keinen Wert. Sie sind also NULL.
Wird ein bestehender Datensatz geupdated über einen Import oder eine SQL, bekommen nicht gefüllte Felder keinen Wert. Sie sind also ebenfalls NULL.
Wird jedoch ein Datensatz, manuell im Contact Builder geupdated, indem ein vorher gefülltes Feld geleert wird, so bekommt das Feld den Wert “. Dieses Feld enthält somit keinen sichtbaren Wert, es enthält jedoch Meta-Daten wie z.B. die Feldlänge.
Wenn dieser Datensatz nun mit der IS NULL Funktion abgefragt wird, wird der Datensatz in den Ergebnissen ausgeschlossen, da dieser nicht NULL ist sondern den Wert “ enthält.
leer (ausgedrückt als = “):
das Feld enthält keinen sichtbaren Wert, es enthält jedoch Meta-Daten
IS NULL:
das Feld hat gar keinen Wert
Hinweis:
Um sicher zugehen, dass alle Felder ohne sichtbaren Wert eingeschlossen bzw. ausgeschlossen werden, sollten in einer SQL beide Fälle abgefragt werden.
Bsp.:WHERE Field IS NULL and Field = ''
bzw.WHERE Field IS NOT NULL and Field <> ''
SQL JOINs sind nicht nur dazu da, um Datensätze aus unterschiedlichen Data Extensions zu einem Datensatz zusammenzufügen, sondern sie schließen gleichzeitig Datensätze aus.
Wenn der falsche JOIN verwendet wird, kann es passieren, dass Datensätze im Ergebnis fehlen, da sie durch den JOIN ausgeschlossen wurden.
INNER JOIN

Bsp.: FROM Accounts INNER JOIN Contacts
Ein INNER JOIN fügt alle Datensätze zusammen, die in der Schnittmenge beider Data Extensions zu finden sind. Die Account Informationen werden mit den Contact Informationen zu einem Datensatz kombiniert. Gleichzeitig werden jedoch alle Accounts ausgeschlossen, die keinen Contact haben und alle Contacts, die keinen Account haben.
LEFT JOIN
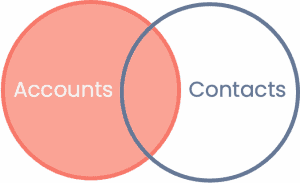
Bsp.: FROM Accounts LEFT JOIN Contacts
Ein LEFT JOIN nimmt ausnahmslos alle Accounts und fügt diejenigen Accounts mit den Contacts zusammen, die in der Schnittmenge zu finden sind. Gleichzeitig werden alle Contacts ausgeschlossen, die keinen Account haben.
Bleib schlau und melde dich hier an:
Wir gehen mit deinen Daten sehr gewissenhaft um und schützen sie wie unsere eigenen. Außerdem ist ein Abmelden jederzeit möglich.

Das Salesforce Summer 26 Release vom Juni 2026 bringt zahlreiche spannende Neuerungen und Verbesserungen, die dir helfen, deine Arbeitsabläufe zu optimieren und effizienter zu gestalten.…

Salesforce zentralisiert sein Schulungs- und Zertifizierungsmodell Salesforce führt ab Mitte 2025 tiefgreifende Änderungen im gesamten Schulungs- und Zertifizierungsprogramm durch. Ziel ist eine klare Zentralisierung aller…

Das Salesforce Spring 26 Release vom Januar / Februar 2026 bringt zahlreiche spannende Neuerungen und Verbesserungen, die dir helfen, deine Arbeitsabläufe zu optimieren und effizienter…
Bleib schlau und melde dich hier an:
Wir gehen mit deinen Daten sehr gewissenhaft um und schützen sie wie unsere eigenen. Außerdem ist ein Abmelden jederzeit möglich.
Sie sehen gerade einen Platzhalterinhalt von Vimeo. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr Informationen